YOLO 目标检测算法学习笔记(三)
YOLO-V1
YOLO,全称 You Only Look Once。名字已经说明了一切!
YOLO 这是一个经典的 one-stage 方法,把检测问题转换为回归问题,一个CNN就可以搞定。
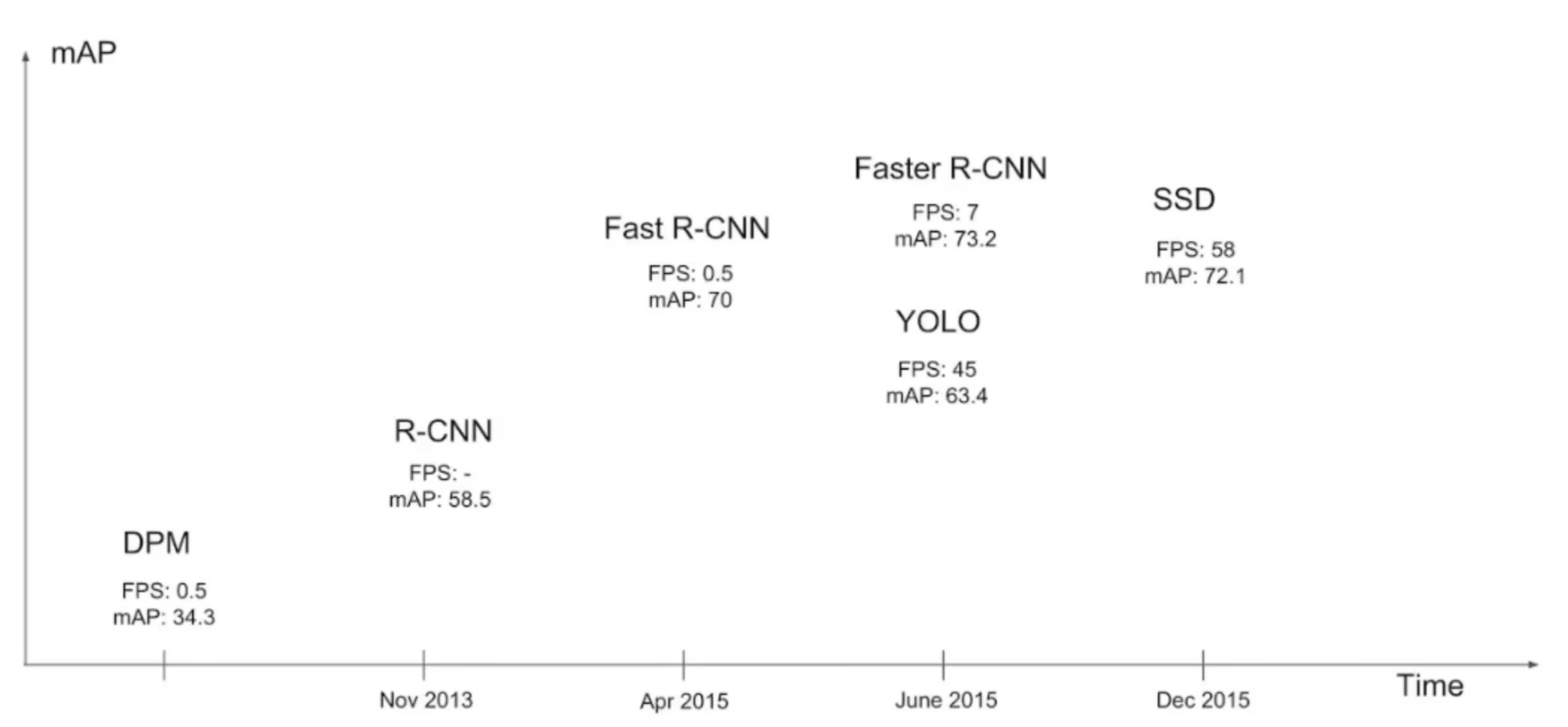
YOLO 相比于 Faster R-CNN 虽然在 mAP 值上略逊一筹,但其 FPS 值是远远高于 Faster R-CNN 的,因此2016年的时,YOLO爆火。
核心思想
- 将输入图像分割成 SxS 个网格(如7x7),每个网格负责检测本身区域是否含有物体。
- 每个网格会预测 B 个边界框(在YOLO-V1中,B值等于2),边界框由四个变量表示 x、y、w、h,以及每个边界框的置信度,置信度用 c 表示。置信度表示边界框包含物体的概率。
-
过滤掉置信度低的边界框。
-
由于整个检测只需要一个前向传播,没有区域提议生成候选框的过程,所以速度非常快。
网络架构
将输入图像(在YOLO-V1中限制了输入图像的大小)进行通过卷积神经网络进行特征提取,获得 7x7x1024 的特征图,再进入全连接层,得到 1470 个特征,随后 Reshape 成 7x7x30 的特征图。
下面解释一下 7x7x30 的含义。
-
7x7 表示输入图像最后分割的网格大小。
-
30 分为 5+5+20,其中前两个5代表两个边界框的 x、y、w、h和c;最后的20表示当前格子属于数据集中的各个类别的概率。
注意,这里三个值都不是固定不变的,会由于YOLO版本的更新和训练数据集的变化而改变。
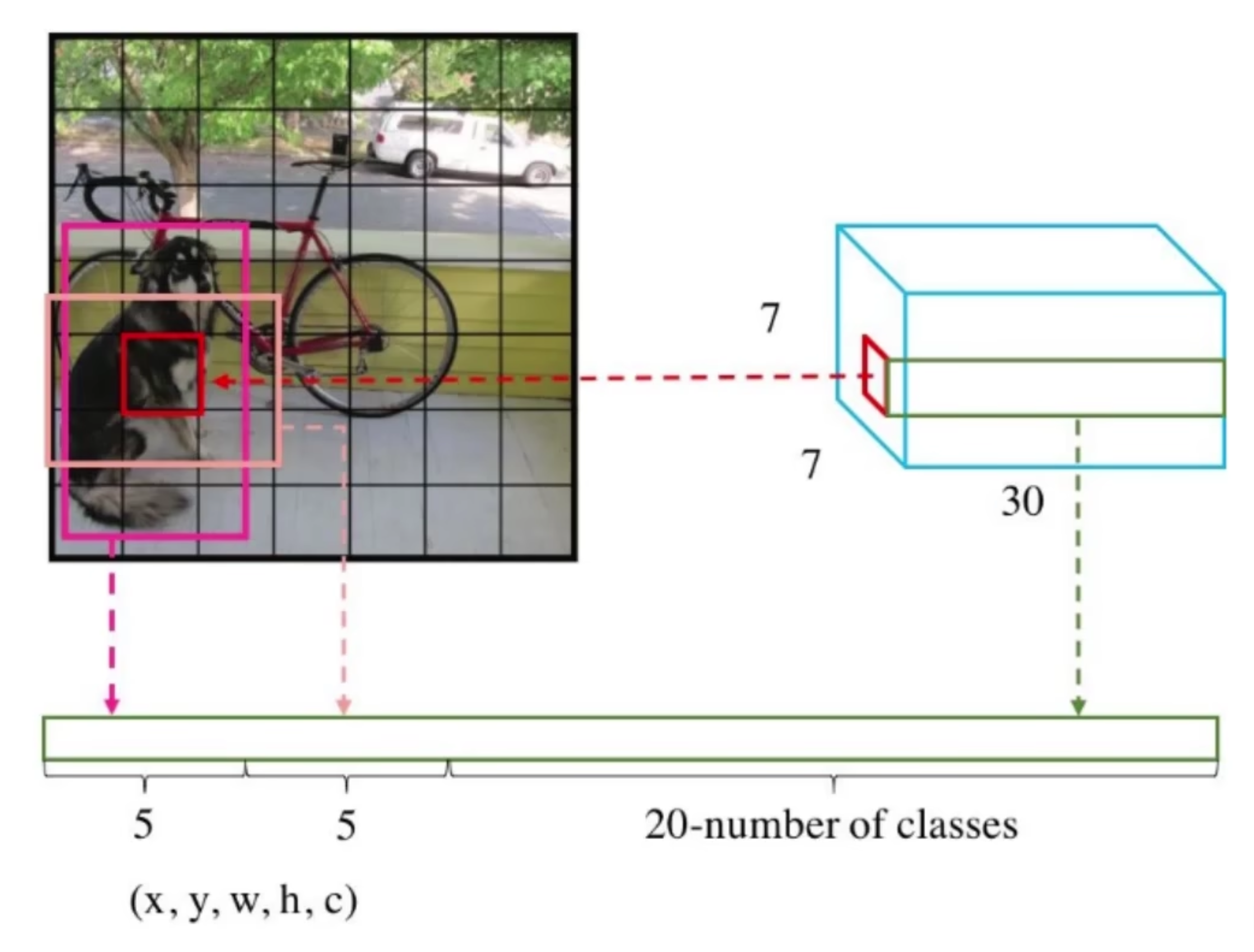
总结一下 ,如上图所示,输入图像最后会被分割成许多个网格,每个网格都包含了若干值。
S:网格边长;B:预测边界框数量;C:数据集中的类别个数。 $$ (S * S) * (B * 5 + C) $$
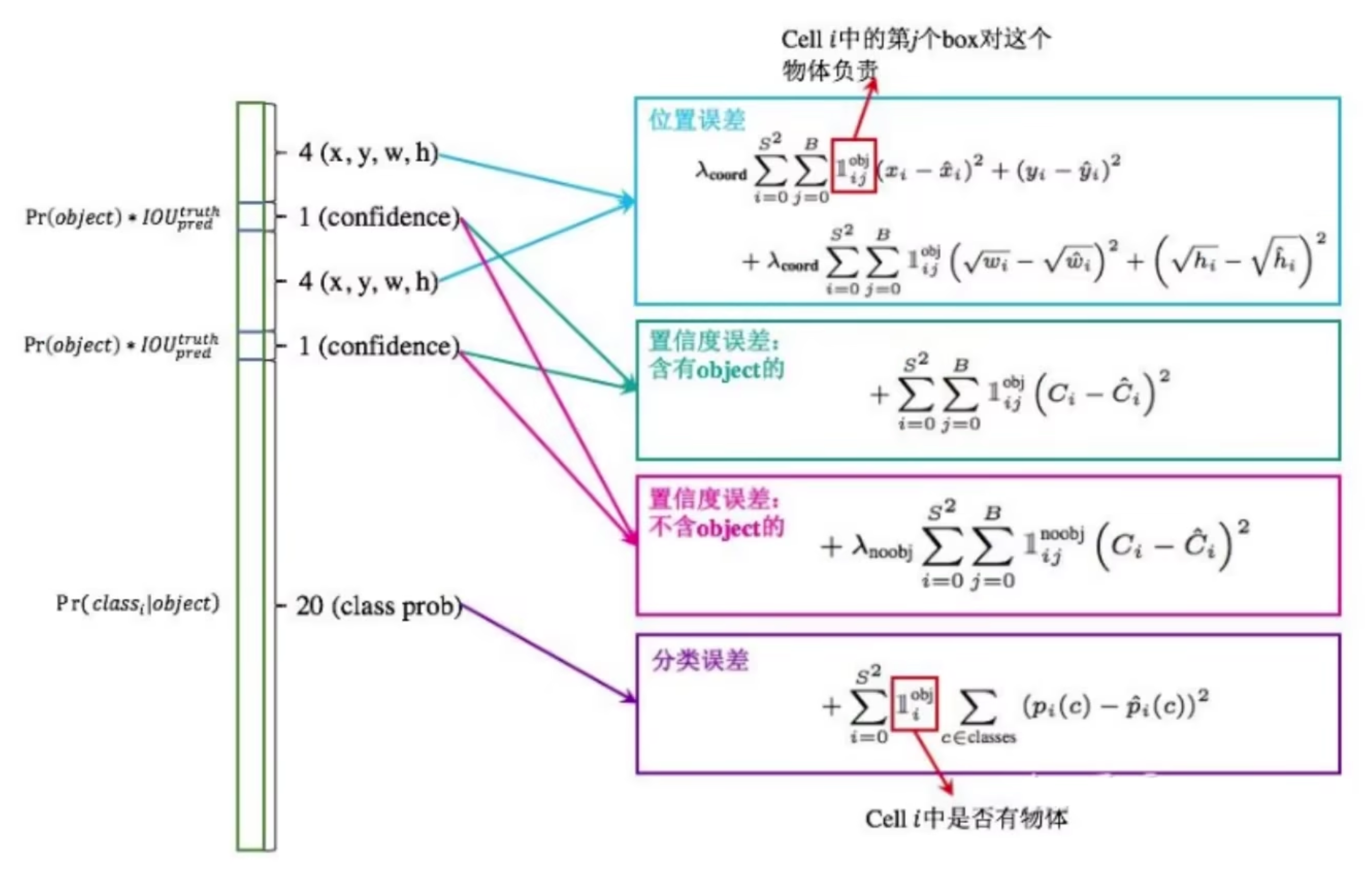
损失函数